The post Instalación Java 8 en Linux Mint appeared first on Developando.com.
]]>La instalación de Java 8 es muy sencilla, a continuación te detallamos los pasos para completarla con éxito:
En primer lugar lo que vamos a realizar es la descarga del fichero empaquetado correspondiente. Esta descarga se puede hacer desde la web de Oracle, sin embargo, de esta manera evitamos la aceptación de licencia.
# cd /opt # wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u72-b15/jdk-8u72-linux-x64.tar.gz # tar xvf jdk-8u72-linux-x64.tar.gz
instalación de java 8 con alternatives
Una vez realizada la descarga y desempaquetado del fichero en el directorio opt realizamos los siguientes pasos:
# sudo update-alternatives --install /usr/bin/java java /opt/jdk1.8.0_72/bin/java 2 # sudo update-alternatives --config java
Cuando ejecutemos update-alternatives nos mostrará un menú textual a través del cual elegir la configuración de java que queremos usar en nuestro sistema. La versión actual activa estará marcada con un asterisco en la parte de la izquierda.
Existen 4 opciones para la alternativa java (que provee /usr/bin/java). Selección Ruta Prioridad Estado ------------------------------------------------------------ 0 /usr/lib/jvm/java-8-oracle/jre/bin/java 1073 modo automático * 1 /opt/jdk1.8.0_72/bin/java 2 modo manual 2 /usr/java/jdk1.6.0_45/bin/java 100 modo manual 3 /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java 1071 modo manual 4 /usr/lib/jvm/java-8-oracle/jre/bin/java 1073 modo manual Pulse <Intro> para mantener el valor por omisión [*] o pulse un número de selección: 2
comprobar la instalación de java
Finalmente para comprobar que hemos realizado bien la instalación de java 8 basta con que escribamos en la consola
# java −version java version "1.8.0_72" Java(TM) SE Runtime Environment (build 1.8.0_72−b15) Java HotSpot(TM) 64−Bit Server VM (build 25.72−b15, mixed mode)
En resumen
Como véis es muy sencillo instalar java 8 en nuestro sistema. Cualquier duda o problema no dudes en escribir un comentario.
The post Instalación Java 8 en Linux Mint appeared first on Developando.com.
]]>The post Java fuentes adicionales generación PDF con JasperReports appeared first on Developando.com.
]]>Para la generación de PDFs desde Java vamos a utilizar la librería “jasperreports-6.0.4.jar” que se puede incluir fácilmente en un proyecto maven añadiendo la siguiente dependencia:
- <dependency>
- <groupId>net.sf.jasperreports</groupId>
- <artifactId>jasperreports</artifactId>
- <version>6.0.4</version>
- </dependency>
Esto incluirá en nuestro proyecto una libraría con el nombre “jasperreports-6.0.4.jar”. También se puede añadir una librería adicional de jasperreports que contiene una extensión con diferentes fuentes utilizando la siguiente dependencia en maven:
- <dependency>
- <groupId>net.sf.jasperreports</groupId>
- <artifactId>jasperreports-fonts</artifactId>
- <version>6.0.0</version>
- </dependency>
Con estas dos librerías en nuestro proyecto podremos crear informes en PDF pero veremos que si utilizamos alguna fuentes por ejemplo en negrita, en el PDF que se genera no se verán estos caracteres en negrita, sino que serán impresos con la fuente por defecto de jasperReports.
Añadir nuevas fuentes
En este tutorial vamos a añadir dos nuevas fuentes para “Arial” y “Arial bold”, que nos permitirá poder generar informes utilizando la fuente arial normal y negrita. Para ello lo que vamos a generar es una nueva librería en la que incluiremos los ficheros de las fuentes y un fichero XML con el “índice” de fuentes que se han incluido.
1.- Crear proyecto Eclipse
Creamos un proyecto Java nuevo en Eclipse y en la carpeta raíz del proyecto vamos a crear el fichero de propiedades que se necesita para configurar la nuevas fuentes de JasperReports. Este fichero se debe llamar “jasperreports_extension.properties“, y tendrá un contenido como el siguiente:
- net.sf.jasperreports.extension.registry.factory.fonts=net.sf.jasperreports.engine.fonts.SimpleFontExtensionsRegistryFactory
- net.sf.jasperreports.extension.simple.font.families.myfamily=fonts/listado-fuentes.xml
De las líneas anteriores hay que fijarse en el nombre del fichero donde se incluirán las diferentes familias de fuentes que se van a añadir, en nuestro ejemplo se llama “listado-fuentes.xml“.
2.- Incluir fichero fuentes (.ttf)
El siguiente paso es incluir en el proyecto los ficheros “.ttf” de cada una de las fuentes que queramos añadir. Para ello creamos una nueva carpeta con el nombre “fonts” y añadimos en ella cada uno de estos ficheros, en nuestro ejemplo añadiremos los ficheros “arial.ttf” y “arialbd.ttf”.
En esta misma carpeta “fonts” debemos crear el fichero con el nombre “listado-fuentes.xml” con el listado de todas las familias de fuentes a incluir, en nuestro caso la familia sera “arial” pero añadimos tanto la fuente normal como en negrita:
- <?xml version="1.0" encoding="UTF-8"?>
- <fontFamilies>
- <fontFamily name="Arial">
- <normal><![CDATA[fonts/arial.ttf]]></normal>
- <bold><![CDATA[fonts/arialbd.ttf]]></bold>
- </fontFamily>
- </fontFamilies>
3.- Generación librería MisFuentes.jar
Una vez completados los pasos anteriores únicamente queda empaquetar el proyecto y generear un fichero “.jar” para añadir al proyecto java con el que se generarán los informes en PDF con la librería de JasperReports. Para esto vamos a crear un fichero “build.xml” de ant con el siguiente contenido, este fichero también lo creamos en el raíz del proyecto del Eclipse:
- <project name="MisFuentes" >
- <target name="crear-jar">
- <mkdir dir="build/jar"/>
- <jar destfile="build/jar/MisFuentes.jar">
- <fileset refid='files.for.jar'/>
- <manifest>
- <attribute name='Specification-Version' value='1.0'/>
- <attribute name='Specification-Title' value='Mis fuentes' />
- </manifest>
- </jar>
- </target>
- <fileset id="files.for.jar" dir=".">
- <include name="fonts/*"/>
- <include name="jasperreports_extension.properties"/>
- </fileset>
- </project>
Ejecutando la tarea ant que hemos llamado “crear-jar” obtendremos el fichero “MisFuentes.jar” que únicamente deberemos añadir a las librerías del proyecto Java desde el que se van a generar los informes en PDF mediante JasperReports.
Con esto ya tendemos las fuentes “Arial” disponibles en nuestros informes.
The post Java fuentes adicionales generación PDF con JasperReports appeared first on Developando.com.
]]>The post Java, Comprobar si un número está contenido en un array appeared first on Developando.com.
]]>Partiremos de la definición de un array de enteros en Java con los posibles valores con los que vamos a trabajar:
- public static final int [] = {1,2,3,6,7,8,56,9,86};
Ahora comprobaremos si un número que se pasa por parámetro está contenido en dicha lista. Para ello vamos a ver en el siguiente ejemplo como convertir el array en una objecto lista gracias al método “asList” de la clase “java.util.Arrays“, para poder utilizar la función “contains” incluida en la clase “java.util.List“:
- public boolean estaEnArray(int numero){
- Arrays.asList(permitidos).contains(numero);
- }
Ejecutando este método obtendremos “true” si el número aparece en el listado que hemos definido en la clase, o ‘false’ si no está incluido:
- estaEnArray(86);// Devuelve true
- estaEnArray(13);// Devuelve false
The post Java, Comprobar si un número está contenido en un array appeared first on Developando.com.
]]>The post Java, convertir Date a XMLGregorianCalendar appeared first on Developando.com.
]]>
- public static XMLGregorianCalendar getXmlGregorianCalendarFromDate(final Date date) throws DatatypeConfigurationException{
- GregorianCalendar calendar = new GregorianCalendar();
- calendar.setTime(date);
- return DatatypeFactory.newInstance().newXMLGregorianCalendar(calendar);
- }
Así de sencillo en convertir un objeto “Date” a “XMLGregorianCalendar” en Java.
The post Java, convertir Date a XMLGregorianCalendar appeared first on Developando.com.
]]>The post Apache POI, leer fichero Excel desde Java appeared first on Developando.com.
]]>Antes de comenzar a trabajar hay que saber si se va a leer un fichero excel con extensión “xls”, que se corresponde con ficheros excel 97 al 2007, o un fichero Excel con extensión “xlsx”, versiones mayores al 2007. En función del tipo de fichero Excel con el que vamos a trabajar deberemos utilizar unas clases u otras.
Lectura ficheros Excel 97-2007 (.xls)
Para la lectura de este tipo de ficheros excel vamos a utilizar el API de POI-HSSF. Para descargar el fichero “poi-3.11.jar” hay que acceder a la página de descargas de apache.
Una vez tenemos el fichero “poi-3.11.jar” o el correspondiente con la versión más actual lo incluimos el proyecto java. El siguiente código muestra cómo leer todas las filas de una hoja excel:
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.IOException;
- import java.util.Iterator;
- import org.apache.poi.hssf.usermodel.HSSFSheet;
- import org.apache.poi.hssf.usermodel.HSSFWorkbook;
- import org.apache.poi.ss.usermodel.Cell;
- import org.apache.poi.ss.usermodel.Row;
- public class LeerExcel {
- public static void main(String args[]) throws IOException{
- FileInputStream file = new FileInputStream(new File("C:\\prueb_excel.xls"));
- // Crear el objeto que tendra el libro de Excel
- HSSFWorkbook workbook = new HSSFWorkbook(file);
- /*
- * Obtenemos la primera pestaña a la que se quiera procesar indicando el indice.
- * Una vez obtenida la hoja excel con las filas que se quieren leer obtenemos el iterator
- * que nos permite recorrer cada una de las filas que contiene.
- */
- HSSFSheet sheet = workbook.getSheetAt(0);
- Iterator<Row> rowIterator = sheet.iterator();
- Row row;
- // Recorremos todas las filas para mostrar el contenido de cada celda
- while (rowIterator.hasNext()){
- row = rowIterator.next();
- // Obtenemos el iterator que permite recorres todas las celdas de una fila
- Iterator<Cell> cellIterator = row.cellIterator();
- Cell celda;
- while (cellIterator.hasNext()){
- celda = cellIterator.next();
- // Dependiendo del formato de la celda el valor se debe mostrar como String, Fecha, boolean, entero...
- switch(celda.getCellType()) {
- case Cell.CELL_TYPE_NUMERIC:
- if( HSSFDateUtil.isCellDateFormatted(celda) ){
- System.out.println(celda.getDateCellValue());
- }else{
- System.out.println(celda.getNumericCellValue());
- }
- System.out.println(celda.getNumericCellValue());
- break;
- case Cell.CELL_TYPE_STRING:
- System.out.println(celda.getStringCellValue());
- break;
- case Cell.CELL_TYPE_BOOLEAN:
- System.out.println(celda.getBooleanCellValue());
- break;
- }
- }
- }
- // cerramos el libro excel
- workbook.close();
- }
- }
Lectura ficheros Excel (.xlsx)
Para poder trabajar con ficheros excel con extensión ‘.xlsx’ debemos añadir las siguientes librerías en nuestro proyecto java:
- poi-3.11.jar
- poi-ooxml-3.11.jar
- poi-ooxml-schemas-3.11.jar
- xmlbeans-2.6-0.jar
Tras incluir las librerías anteriores en nuestro proyecto Jata, y con el siguiente código recorreríamos todas las celdas contenidas en las primera hoja del libro excel.
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.IOException;
- import java.util.Iterator;
- import org.apache.poi.ss.usermodel.Cell;
- import org.apache.poi.ss.usermodel.Row;
- import org.apache.poi.xssf.usermodel.XSSFSheet;
- import org.apache.poi.xssf.usermodel.XSSFWorkbook;
- public class LeerExcel {
- public static void main(String args[]) throws IOException{
- FileInputStream file = new FileInputStream(new File("C:\\prueb_excel.xls"));
- // Crear el objeto que tendra el libro de Excel
- XSSFWorkbook workbook = new XSSFWorkbook(file);
- /*
- * Obtenemos la primera pestaña a la que se quiera procesar indicando el indice.
- * Una vez obtenida la hoja excel con las filas que se quieren leer obtenemos el iterator
- * que nos permite recorrer cada una de las filas que contiene.
- */
- XSSFSheet sheet = workbook.getSheetAt(0);
- Iterator<Row> rowIterator = sheet.iterator();
- Row row;
- // Recorremos todas las filas para mostrar el contenido de cada celda
- while (rowIterator.hasNext()){
- row = rowIterator.next();
- // Obtenemos el iterator que permite recorres todas las celdas de una fila
- Iterator<Cell> cellIterator = row.cellIterator();
- Cell celda;
- while (cellIterator.hasNext()){
- celda = cellIterator.next();
- // Dependiendo del formato de la celda el valor se debe mostrar como String, Fecha, boolean, entero...
- switch(celda.getCellType()) {
- case Cell.CELL_TYPE_NUMERIC:
- if( DateUtil.isCellDateFormatted(celda) ){
- System.out.println(celda.getDateCellValue());
- }else{
- System.out.println(celda.getNumericCellValue());
- }
- break;
- case Cell.CELL_TYPE_STRING:
- System.out.println(celda.getStringCellValue());
- break;
- case Cell.CELL_TYPE_BOOLEAN:
- System.out.println(celda.getBooleanCellValue());
- break;
- }
- }
- }
- // cerramos el libro excel
- workbook.close();
- }
- }
The post Apache POI, leer fichero Excel desde Java appeared first on Developando.com.
]]>The post Java, leer y guardar fichero desde una URL appeared first on Developando.com.
]]>Partimos de la URL donde esté alojado el fichero, por ejemplo:
http://midominio.es/carpeta/10/01/2012/plantilla.txt
Mostrar en pantalla el contenido del fichero dada la URL
En este ejemplo vamos a mostrar un método que cargue un fichero dada su URL y muestre en pantalla línea a línea el contenido de dicho fichero. Para ello vamos a crear un método llamado “mostrarContenido” que dada una URL recupere un fichero y muestre el contenido en la consola:
public static void mostrarContenido(String url) throws Exception {
URL ficheroUrl = new URL(url);
BufferedReader in = new BufferedReader(new InputStreamReader(ficheroUrl.openStream()));
String linea;
while ((linea = in.readLine()) != null){
System.out.println(linea);
}
in.close(); // Cerramos la conexión
}
Descargar un fichero dada la URL
Si lo que queremos hacer es que dada una URL descarguemos el contenido del fichero y creemos un nuevo fichero (java.io.File) en Java deberemos utilizar este otro método llamado “descargarUrl”. Este método recibe por parámetro la URL donde está alojado el fichero y también la ruta y el nombre donde queremos crear el nuevo fichero:
public static void descargar(String url, String ficheroDestino) throws Exception {
URL ficheroUrl = new URL(url);
InputStream inputStream = ficheroUrl.openStream();
OutputStream outputStream = new FileOutputStream(ficheroDestino); // path y nombre del nuevo fichero creado
byte[] b = new byte[2048];
int longitud;
while ((longitud = inputStream.read(b)) != -1) {
outputStream.write(b, 0, longitud);
}
inputStream.close(); // Cerramos la conexión entrada
outputStream.close(); // Cerramos la conexión salida
}
The post Java, leer y guardar fichero desde una URL appeared first on Developando.com.
]]>The post Java 7 : Leer y escribir ficheros de texto en Java appeared first on Developando.com.
]]>- Paths y Path – Localización del fichero o nombre, no su contenido.
- Files - Operaciones con el contenido del fichero.
- StandardCharsets y Charset - Para manejar la codificación del archivo de texto.
- File.toPath – Método que permite interactuar con código antiguo a través del nuevo API java.nio
Las siguientes clases también son usadas de manera generalizada cuando trabajamos con ficheros de texto tanto en Java 7 como en versiones anteriores:
- Scanner – Permite leer ficheros de una manera sencilla.
- BufferedReader - Permite accesos de lectura línea a línea.
- BufferedWriter - Permite accesos de escritura línea a línea.
Cuando realizamos operaciones de lectura/escritura con ficheros de texto:
- Frecuentemente será buena idea utilizar buffering (por defecto el tamaño son 8K)
- Siempre tendremos que tener en cuenta el manejo de excepciones de IOException y FileNotFoundException.
java 7 : Codificación de caracteres
Para realizar operaciones sobre ficheros de texto en Java 7 tenemos que tener en cuenta que esas operaciones de lectura/escritura siempre usan una codificación de caracteres de manera implícita para traducir las cadenas de bytes en texto. Aquí es donde frecuentemente nos encontramos antes el primer problema.
Las clases FileReader y FileWriter utilizan de manera implícita la codificación de caracteres del sistema. Sin embargo, no es apropiado utilizarlo debido a los problemas que puede ocasionar usar nuestro código en diferentes sistemas operativos por ejemplo. La manera correcta es emplear aquellas clases que nos obliguen a realizar una declaración explícita de la codificación de caracteres como por ejemplo:
- FileInputStream fis = new FileInputStream("test.txt");
- InputStreamReader in = new InputStreamReader(fis, "UTF-8");
- FileOutputStream fos = new FileOutputStream("test.txt");
- OutputStreamWriter out = new OutputStreamWriter(fos, "UTF-8");
- Scanner scanner = new Scanner(file, "UTF-8");
java 7 + ejemplo 1
- package es.ivoto.cera.config;
- import java.io.BufferedReader;
- import java.io.BufferedWriter;
- import java.io.IOException;
- import java.nio.charset.Charset;
- import java.nio.charset.StandardCharsets;
- import java.nio.file.Files;
- import java.nio.file.Path;
- import java.nio.file.Paths;
- import java.util.Arrays;
- import java.util.List;
- import java.util.Scanner;
- public class LeerEscribirFicheroTextoJDK7 {
- public static void main(String... aArgs) throws IOException{
- LeerEscribirFicheroTextoJDK7 text = new LeerEscribirFicheroTextoJDK7();
- //Tratamiento con fichero pequeño con Java 7
- List<String> lines = text.readSmallTextFile(FILE_NAME);
- log(lines);
- lines.add("Esta es una línea añadida desde el código.");
- text.writeSmallTextFile(lines, FILE_NAME);
- //Tratamiento para ficheros grandes usando buffering
- text.readLargerTextFile(FILE_NAME);
- lines = Arrays.asList("Down to the Waterline", "Water of Love");
- text.writeLargerTextFile(OUTPUT_FILE_NAME, lines);
- }
- final static String FILE_NAME = "C:\Temp\input.txt";
- final static String OUTPUT_FILE_NAME = "C:\Temp\output.txt";
- final static Charset ENCODING = StandardCharsets.UTF_8;
- //Para ficheros pequeños. Java 7
- /**
- Nota: el javadoc de Files.readAllLines dice que es recomendable para pequeños ficheros.
- Pero su implementación usa buffering, por lo que también es recomendable para usarlo
- con ficheros de texto de mayor tamaño.
- */
- List<String> readSmallTextFile(String aFileName) throws IOException {
- Path path = Paths.get(aFileName);
- return Files.readAllLines(path, ENCODING);
- }
- void writeSmallTextFile(List<String> aLines, String aFileName) throws IOException {
- Path path = Paths.get(aFileName);
- Files.write(path, aLines, ENCODING);
- }
- //Para ficheros grandes Java 7
- void readLargerTextFile(String aFileName) throws IOException {
- Path path = Paths.get(aFileName);
- try (Scanner scanner = new Scanner(path, ENCODING.name())){
- while (scanner.hasNextLine()){
- //procesa cada línea del mismo modo
- log(scanner.nextLine());
- }
- }
- }
- void readLargerTextFileAlternate(String aFileName) throws IOException {
- Path path = Paths.get(aFileName);
- try (BufferedReader reader = Files.newBufferedReader(path, ENCODING)){
- String line = null;
- while ((line = reader.readLine()) != null) {
- //procesa cada línea del mismo modo
- log(line);
- }
- }
- }
- void writeLargerTextFile(String aFileName, List<String> aLines) throws IOException {
- Path path = Paths.get(aFileName);
- try (BufferedWriter writer = Files.newBufferedWriter(path, ENCODING)){
- for(String line : aLines){
- writer.write(line);
- writer.newLine();
- }
- }
- }
- private static void log(Object aMsg){
- System.out.println(String.valueOf(aMsg));
- }
- }
java 7 + : Ejemplo 2
Este ejemplo muestra el uso de Scanner con Java 7 para leer un archivo que contiene las líneas de datos estructurados. Un Scanner se utiliza para leer en cada línea, y un segundo Scanner se utiliza para analizar cada línea en un simple par nombre-valor. La clase Scanner sólo se utiliza para la lectura, no para la escritura.

Java 7 : Clase Scanner
- package es.ivoto.cera.config;
- import java.io.IOException;
- import java.nio.charset.Charset;
- import java.nio.charset.StandardCharsets;
- import java.nio.file.Path;
- import java.nio.file.Paths;
- import java.util.Scanner;
- /**Asumimos que el fichero está codificado en UTF-8. Java 7 +. */
- public class LeerConScanner {
- public static void main(String... aArgs) throws IOException {
- LeerConScanner parser = new LeerConScanner("C:\Temp\test.txt");
- parser.processLineByLine();
- log("Done.");
- }
- /**
- Constructor.
- @param aFileName nombre completo de un fichero existente.
- */
- public LeerConScanner(String aFileName){
- fFilePath = Paths.get(aFileName);
- }
- /** Método que invoca a {@link #processLine(String)}. */
- public final void processLineByLine() throws IOException {
- try (Scanner scanner = new Scanner(fFilePath, ENCODING.name())){
- while (scanner.hasNextLine()){
- processLine(scanner.nextLine());
- }
- }
- }
- /**
- Método sobreescribible para procesar las líneas de diferentes maneras.
- <P>La implementación por defecto espera recibir pares de clave-valor separados por un '='.
- Ejemplo de entradas válidas:
- <tt>height = 178cm</tt>
- <tt>mass = 95kg</tt>
- <tt>disposition = "grumpy"</tt>
- <tt>Clave = valor</tt>
- */
- protected void processLine(String aLine){
- Scanner scanner = new Scanner(aLine);
- scanner.useDelimiter("=");
- if (scanner.hasNext()){
- String name = scanner.next();
- String value = scanner.next();
- log("Name is : " + quote(name.trim()) + ", and Value is : " + quote(value.trim()));
- }
- else {
- log("Línea vacía o sin la estructura esperada. No se puede procesar.");
- }
- }
- // PRIVADO
- private final Path fFilePath;
- private final static Charset ENCODING = StandardCharsets.UTF_8;
- private static void log(Object aObject){
- System.out.println(String.valueOf(aObject));
- }
- private String quote(String aText){
- String QUOTE = "'";
- return QUOTE + aText + QUOTE;
- }
- }
Si ejecutas el ejemplo se obtendrá:
- Name is : 'height', and Value is : '167cm'
- Name is : 'mass', and Value is : '65kg'
- Name is : 'disposition', and Value is : '"grumpy"'
- Name is : 'this is the name', and Value is : 'this is the value'
- Done.
The post Java 7 : Leer y escribir ficheros de texto en Java appeared first on Developando.com.
]]>The post Garbage Collector: Intepretando su salida appeared first on Developando.com.
]]>Configurar el Garbage Collector para que nos de esta salida es bastante sencillo. En mi caso el entorno es el siguiente:
Eclipse Kepler + Java 7 + Tomcat 7
He modificado la configuración de arranque del Tomcat para añadirle los siguientes parámetros:

Con estos parámetros la salida que obtenemos es la siguiente salida en nuestra consola:
- [GC [PSYoungGen: 72686K->5110K(72704K)] 86900K->32995K(159744K), 0.0176918 secs] [Times: user=0.03 sys=0.02, real=0.02 secs]
- [GC [PSYoungGen: 72694K->17904K(148992K)] 100579K->47708K(236032K), 0.0199841 secs] [Times: user=0.03 sys=0.02, real=0.02 secs]
- [GC [PSYoungGen: 148976K->21989K(153088K)] 178780K->70001K(240128K), 0.0362913 secs] [Times: user=0.11 sys=0.00, real=0.03 secs]
- [GC [PSYoungGen: 153061K->34787K(283136K)] 201073K->100969K(370176K), 0.0318076 secs] [Times: user=0.08 sys=0.00, real=0.04 secs]
- [Full GC [PSYoungGen: 34787K->0K(283136K)] [ParOldGen: 66182K->49354K(117248K)] 100969K->49354K(400384K) [PSPermGen: 18093K->18089K(36352K)], 0.1232627 secs] [Times: user=0.34 sys=0.00, real=0.11 secs]
- [GC [PSYoungGen: 248320K->48632K(296960K)] 297674K->103225K(414208K), 0.0427160 secs] [Times: user=0.11 sys=0.01, real=0.06 secs]
- [GC [PSYoungGen: 296952K->58861K(387072K)] 351545K->127707K(504320K), 0.0549142 secs] [Times: user=0.11 sys=0.03, real=0.05 secs]
- [GC [PSYoungGen: 387053K->36470K(401920K)] 455899K->142959K(519168K), 0.0577764 secs] [Times: user=0.16 sys=0.00, real=0.06 secs]

Pues si esta es la cara que se te queda al ver lo que el Garbage Collector escupe en tu consola estás leyendo el post adecuado. Como decía, en el Codemotion @alotor nos enseño una diapo en la que al menos pudimos saber relacionar las trazas con los tipos de procesos del Garbage Collector (recolección de jóvenes y STW stop the world) como se ve en la siguiente imagen:
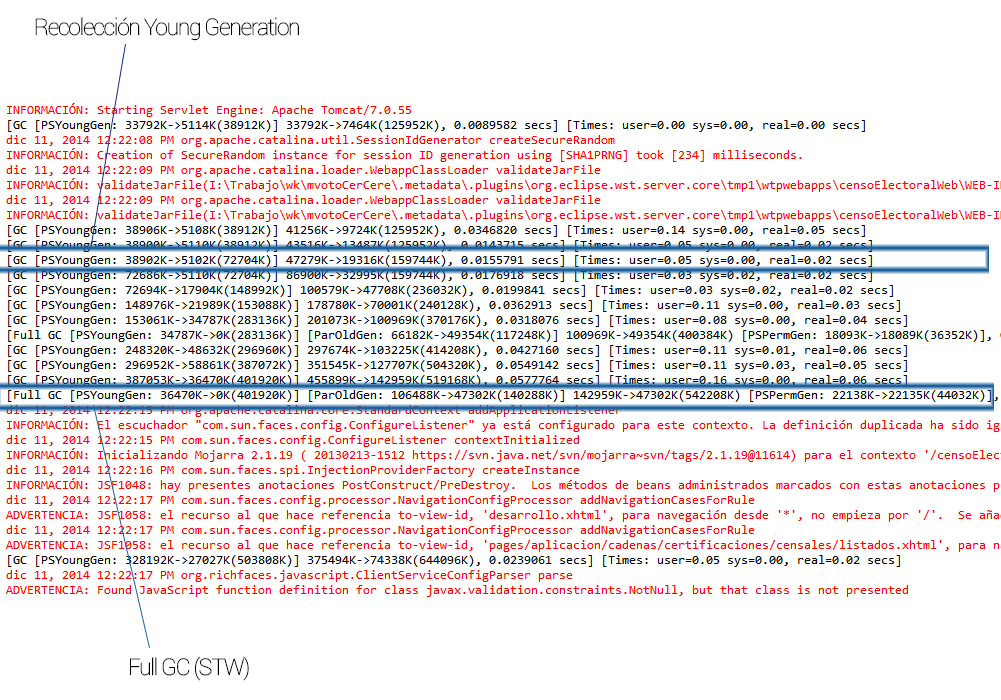
Dado que es un tema extenso se tocaron unos cuantos temas más sin profundizar en demasía aunque dejando el camino trillado para poder seguir investigando sobre el Garbage Collector.
Vamos a analizar el detalle de la salida con el siguiente ejemplo para ver qué está queriendo decir el Garbage Collector:
- [GC [PSYoungGen: 387053K->36470K(401920K)] 455899K->142959K(519168K), 0.0577764 secs] [Times: user=0.16 sys=0.00, real=0.06 secs]
Descripción de la salida del Garbage Collector
[GC [PSYoungGen: 387053K->36470K(401920K)]
GC indica el que el Garbage Collector que ha entrado en acción no es un [Full GC] ya que en ese caso aparecería ese tipo indicado como se puede ver en el ejemplo de más arriba.
PSYoungGen nos dice que tipo de collector se emplea. PSYoungGen es el recolector de jóvenes.
387053K indica el tamaño de la región de jóvenes antes de la ejecución del Garbage Collector.
36470K indica valor posterior a la ejecución del GC que ocupa la región de jóvenes. Cuánto menor sea su número mejor puesto que significará que ha liberado más espacio de memoria.
401920K valor máximo de memoria que puede ocupar la región de jóvenes.
455899K->142959K(519168K), 0.0577764 secs]
455899K tamaño total ocupado en el heap antes de la ejecución del Garbage Collector.
142959K tamaño resultante de la ejecución de GC.
519168K valor del tamaño máximo del heap.
0.0577764 secs tiempo invertido en realizar la operación de liberación de espacio de memoria heap.
conclusiones
Como hemos podido ver es mucho más sencillo ahora entender un poco qué es lo que ocurre y hace el Garbage Collector cuando añadimos los parámetros necesarios para tracear su actividad.
¡ Todos los comentarios son bien recibidos !
The post Garbage Collector: Intepretando su salida appeared first on Developando.com.
]]>The post Spring ha muerto … ¡larga vida a Spring! appeared first on Developando.com.
]]>Las slides de la charla también están accesibles aquí:
http://www.slideshare.net/ilopmar/spring-ha-muerto-larga-vida-a-spring-boot
The post Spring ha muerto … ¡larga vida a Spring! appeared first on Developando.com.
]]>The post OutOfMemoryError : Java Heap Space – Eclipse + Tomcat appeared first on Developando.com.
]]>Al igual que vimos en el caso del timeout por el tiempo de arranque de nuestro Tomcat este tipo de error parece que es más frecuente de lo que desaría cualquiera.
Di ‘nunca más’ la próxima vez que veas un outofmemoryerror
Vamos a nuestros servidores y hacemos doble clic sobre el que queramos actuar.

OutOfMemoryError – paso 1
En la pantalla que nos aparece hacemos clic sobre Open launch configuration

OutOfMemoryError
Haz clic a la pestaña de Arguments, en el apartado de VM Arguments podrás establecer el tamaño del heap de acuerdo a lo siguiente:
-Xms<size> - Set <Tamaño inicial del heap> -Xmx<size> - Set <Tamaño máximo del heap>

OutOfMemoryError
En nuestro caso hemos declarado un heap inicial de 512 megas y un heap máximo de 1024 megas (1 Gb vaya).
¡ Y listo !
PD: Si esto ha solucionado tus problemas me alegro, sin embargo, en la mayoría de ocasiones encontrarnos con este error será un indicativo de que algo no está marchando bien en nuestro desarrollo. Siempre se podrá escalar dotando de mayor memoria al desarrollo para evitarlo pero esto no se puede mantener de manera infinita en el tiempo. Trata de optimizar tu código, si tienes tiempo para ello o cuando lo tengas.
The post OutOfMemoryError : Java Heap Space – Eclipse + Tomcat appeared first on Developando.com.
]]>